
Artificial Intelligence is the new electricity. Everyone talks about it, everyone uses it and some are afraid of losing jobs because of it. Railsware, as a consultancy, is often asked by our partners about AI-driven features which would be great for their applications. Today I want to share with you a story of one of the projects I worked on and how we did not build Artificial Intelligence solution.
The challenge
We faced a challenge of building a quick prototype of an application which could extract specific financial data out of documents. The documents (an input to our system) were in a form of uploaded scanned PDF files. The data we wanted to extract was a set of about 20 metrics, like inflation rates or liabilities.
We had about 3k documents and we did not know which ones were suspected of containing interesting for us financial data. The documents had different number of pages: from short ones with 30 pages to files with about 300 pages. Our partner was hiring a workforce to crunch that number of documents. That process needed to be automated and we had only a few weeks to do it.
The solution
Simplifying it a bit, the data scraping process had two steps. In order to find a specific metric, first we had to look for a page suspected of containing a crucial data. Second, having that page, extract the value. For example, when we wanted to search for company assets in 2017, we had to find a page with a table and in that table to look for the value in the right column.
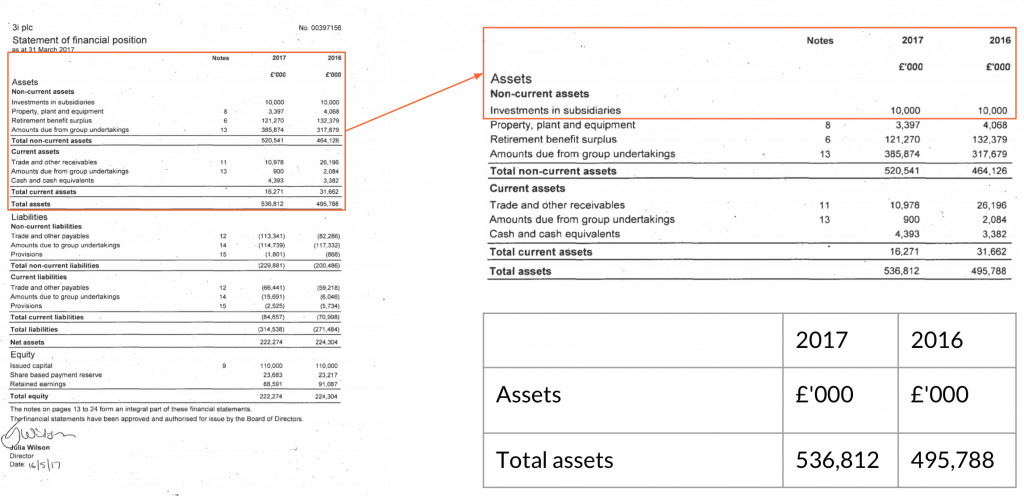
We’ve built a PDF processing pipeline doing conversion from PDF to images and then used advanced Image Search Techniques to locate and extract printed words contained within the images. The tool we have used for that is Google Vision API. It provided us with an unstructured (raw, without layout) text scrapped from images. The output of the pipeline was a set of words found on given report pages.
Our idea was to build a vector of words representing every page.
Having that, we could classify new pages as relevant or not using vector similarity algorithms like euclidean distance.
To the big surprise, this turned out to be quite a challenge. Every company had a different style of composing its reports. There were cases when some pages contained words associated with metrics but did not include values, or tables simply did not have exactly the same headers that we were looking for. Additionally, the Google Vision API was not able to always read the words correctly, which resulted in providing us with splices of words or their misspellings. We had a lot of false positives and false negatives.
So we were only halfway to our original plan of extracting the specific values and we already had a high error rate of detecting relevant pages. But we’ve decided to proceed and see if we can at least extract values from the correctly classified pages.
And here we faced even bigger challenge. From the extracted texts we only knew which words occured on a page but we had no clue on how the layout of that page looks like. It was a time to use AI-powered OCR technology like Abbyy which could detect a table on a given page and convert the image to HTML file which supports table layouts. This does not sound easy anymore and I’m not gonna cover technical details but the outcome of that experiment was not satisfying. We had a lot of simple OCR errors like wrong edge detection, which resulted in a table not being recognised. Extracted tables were missing headers or its layouts were broken. All this meant that we had an error rate (which we measured ourselves) of value extraction on the level of 60%.
After 3 weeks of development, we already knew a few things:
- we had a high error rate of detecting relevant pages
- we had even higher error rate of extracting values
We came to the conclusion that we needed to have a bigger set of labeled data: pages correctly marked as containing the data and some smart algorithm for detecting values in data represented in the tables. We’ve decided to rethink our approach and power our learning process with Artificial Artificial Intelligence.
Artificial Artificial Intelligence
Artificial Artificial Intelligence (AAI) is a concept of application behaving like if it was AI-driven when in practice it was not. How is it possible?
The “Intelligence” in AAI stands for intelligence of a human, not a computer. To make your application smart, you can use human intelligence for performing a huge amount of small tasks.
The working solution
Our new plan was to integrate our processing pipeline with a crowdsourcing platform. This way we could get an advantage of humans being able to correctly detect a table in a document and look for a value inside it.
One of the best known crowdsourcing platforms is Amazon Mechanical Turk. The name derives from famous 18th century chess-playing machine that was operated by a hidden chessmaster. Mechanical Turk is partially a toolkit for software companies and partially an online marketplace, where everyone can register as a Turk (worker) and start performing Human Intelligence Tasks (HITs) requested by companies. The task, depending on our needs, can be of different kinds, like labeling a category of an image, transcribing an audio recording or some more advanced research. Diversification and scale of personnel of Mechanical Turk allow collecting an amount of information that would be difficult outside of a crowd platform.
There is a lot of good resources with explanation how you can integrate your app with MTurk on their blog so I’m not gonna cover that now. All that we need to know is that Mechanical Turk provides an API for requesting tasks and retrieving answers from workers. When scaling similar data collection workflows, using a residential proxy can help ensure stable access to distributed sources and maintain consistent data retrieval across different regions.
We have implemented an integration with Mechanical Turk in a way that part of the work (converting PDF files to images and detecting relevant pages) was performed by our automated pipeline and final metrics detection was requested to workers inside Mechanical Turk platform. As a result we were receiving not only information on pages with needed metrics but also the values themselves. Using the same algorithm as before, we measured our results and in our case the average error rate of workers was on the level of 18%. It was the end of 6th week of development and we had a working solution, yay!
More details on our efforts with the processing pipeline and implementation of two different methods (AI vs AAI) you can find in this presentation by my colleague Artur Hebda:
Final notes

We have achieved our goal with an automated way of extracting financial data from reports. But we do not consider it as a final solution. Having our lessons learnt from trying to do machine-learning-driven automation, we know that we need more labeled data to build the right models. Using AAI means that we not only have a working solution, but also are now collecting a valid set of classified data. This data can be used in the future to train more advanced machine learning models and try to build our fully-automated approach one more time.
The error rates for both solutions show that so far human intelligence is on a completely different level comparing to automated optical character recognition. However both solutions have a chance to conform to huge adjustments if given enough time, efforts and data.